Under the Hood
Basic Description of How SlideRule Works

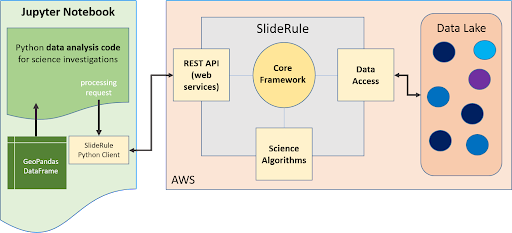
SlideRule System Diagram
There are two main ways to access SlideRule services: the Web Client for interactive and intuitive access, and the Python Client for scripted and fine-grained access. The web-client is distributed via AWS CloudFront and runs entirely as a single page application inside the user’s browser. The Python client heavily leverages GeoPandas and is designed to integrate into both interactive notebooks and repeatable processing pipelines.
SlideRule services are fulfilled by SlideRule servers contained in either public or private clusters. These clusters are provisioned and maintained by the Provisioner which is responsible for starting and stopping clusters of servers in AWS. Working with the Provisioner is the Authenticator which is responsible for authenticating users and issuing JSON Web Tokens (JWT) restricting access to SlideRule resources based on user membership and roles.
Each provisioned cluster is self-contained and ephemeral, meaning it is provisioned when needed, performs its tasks without requiring any other infrastructure, and is then torn down. To do this, the entire system is defined in Cloud Formation template files and created and destroyed using AWS services called by the Provisioner. The consequence of this approach is that nothing is changed in-place. New versions of the code are deployed when new clusters are provisioned. Security patches are applied by rebuilding and redeploying the cluster.
When a provisioned cluster comes up, it fetches and starts a specific set of Docker images specified at the time of deployment Those images are tagged in association with specific software releases. Each container then runs code that periodically registers itself with the Intelligent Load Balancer (ILB). A registration identifies the service that the container fulfills, and provides a lifetime for the registration. All requests to SlideRule services go to through the load balanacer which handles authentication (for private clusters) and rate limiting, and routes the request to the appropriate registered backend service.
Logs and metrics for the cluster are maintained by the Recorder which provides a kinesis firehose stream for both alerts and telemetry messages generated by the rest of the SlideRule system.
The heart of the SlideRule system is an instantiation of the core SlideRule framework on each node in the cluster. The core framework contains internally developed code that accepts processing requests from clients, reads externally hosted science datasets, executes algorithms on the data, and returns results back to the clients.
Running alongside the core framework container on each node is an Asset Metadata Service (AMS). The AMS is responsible for maintaining selected metadata catalogs of Earth science datasets used by SlideRule and for responding to temporal/spatial queries.
SlideRule relies heavily on external services for querying metadata for Earth science data. Specifically, NASA’s Common Metadata Repository and USGS’s The National Map are used for many of the datasets supported by SlideRule. These metadata services point to resources in AWS S3 that are directly accessed by SlideRule when fulfilling processing requests.
Components of a Processing Request
Each processing request to SlideRule consists of these stages.
- Authentication
If accessing the public SlideRule service, authentication is unnecessary. But, if accessing a private cluster, the user authenticate themselves to the Authenticator which generates a JWT that identifies what they can and cannot do.
- Querying available data resources
The datasets necessary to fulfill the request are queried using either geo-spatial or temporal filters, and a set of data resources (e.g. granules) are returned. For example, for ICESat-2, a combination of SlideRule’s internal AMS system and NASA’s CMR system is used to query which resources are available.
- Processing the data
The set of resources that need to be processed are distributed across the available compute nodes, processed, and the results are collected into a GeoDataFrame which is returned to the user upon completion of the request.
Diving down a little deeper, the third stage of each request – processing the data – can be further broken down into three processes:
A SlideRule Cluster’s Primary Functions
- Web Service
When a processing request is made to a SlideRule server, the code that handles the request instantiates a self-contained Lua runtime environment and kicks off a Lua script that is associated with the service being requested. It then creates a pipe from the Lua script back to the end-user’s client so that any data generated by the Lua script flows back to the user as a response. Web services provided by SlideRule can be accessed by any http client (e.g. curl); but different clients are provided by the project to make it easier to interact with SlideRule. These clients provide functional interfaces for making on-demand science data requests: processing parameters are populated, all the necessary requests to the SlideRule servers are performed and the responses from the servers are handled, and the results are collected into DataFrame-like structures and returned back to the calling code.
- Science Algorithms
Science algorithms available to SlideRule are implemented in C++ and Lua code and run inside the SlideRule framework on each server. They are invoked by calls to the web services which kick off Lua scripts, and utilize the data access code to pull in the requested datasets for processing. On the public cluster, the customization of the algorithm processing is limited to predefined parameters made available by the code and exposed to the web service. On private clusters, users can run sandboxed Lua code provided at the time of the request.
- Data Interface
At the start of every algorithm, the set of data needed by the algorithm is internally requested. SlideRule maintains a thread pool of data fetchers that receive those internal requests and perform the data reads asynchronously. The algorithms will do as much as they can with the data they have available and will block until notified by the data fetchers when they need more data to proceed. Data accessed by SlideRule can reside anywhere and be in any format, as long as an appropriate driver is provided. SlideRule treats all datasets as “assets” and requires each asset to be registered in an “asset directory” which provides the asset’s location, format, and associated code needed to access and read the asset. Currently, SlideRule supports (Geo)Parquet, HDF5, and (Geo)TIFFS, both stored locally, in S3, and on the web.
Technology used in SlideRule
The main technologies used to implement SlideRule are Cloud Formation for provisioning resources in AWS, Docker for containerizing the components of the application, and Grafana / Prometheus / Loki for observability.
The primary unit of deployment for SlideRule is the provisioned Cluster which consists of an AWS Autoscaling Group that runs the SlideRule processing nodes and stand-alone EC2 instances that run the load balancer, and monitoring system.
Each EC2 instance in the cluster runs Promtail for log collection and Node Exporter for metric collection. Those processes feed data back to the Monitor which is running Loki for log aggregation, and Prometheus for metric aggregation. The Monitor also runs Grafana which is connected to both Loki and Prometheus and provides dashboard access to developers of the logs and metrics generated by the cluster.
All nodes in a Cluster are orchestrated by an Intelligent Load Balancer (ILB) running HAProxy with custom Lua extensions. Additionally, they have access to a locally running Asset Metadata Service (AMS) which is implemented in Flask and uses DuckDB with spatial extensions for fast temporal and spatial querying.
Inside each node on the cluster, the internally developed SlideRule framework leverages cURL for making HTTP requests, GDAL for raster processing, and an internally developed library called H5Coro for performant access of HDF5 files in S3.
Support services like the Authenticator, Provisioner, and Recorder are implemented in AWS Lambda and use an API Gateway for web access.